 Pythonでインフォマティクス
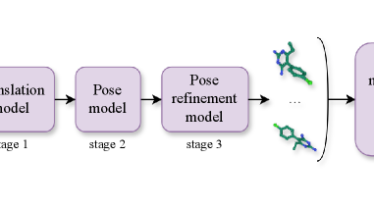
Pythonでインフォマティクス MATCHA:多段階フローマッチングで分子ドッキングの物理的妥当性を改善する
タンパク質と小分子(リガンド)がどのように結合するか、または結合しないのか、正確に予測(ドッキング予測)することができれば、様々な応用が可能です。近年、DiffDock1に代表される拡散モデル(diffusion model)ベースの手法が...
 Pythonでインフォマティクス
Pythonでインフォマティクス  Rでデータ解析と可視化
Rでデータ解析と可視化 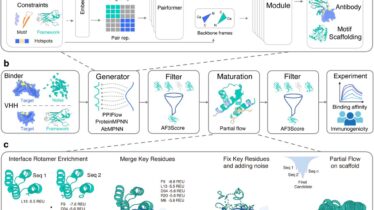 Pythonでインフォマティクス
Pythonでインフォマティクス 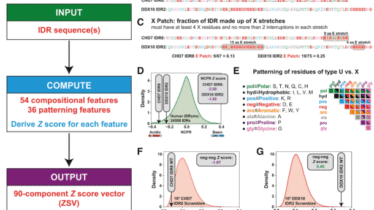 Pythonでインフォマティクス
Pythonでインフォマティクス 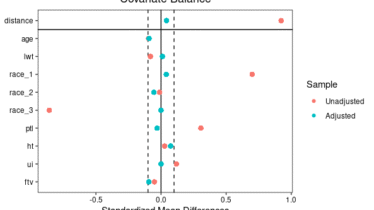 Rでデータ解析と可視化
Rでデータ解析と可視化 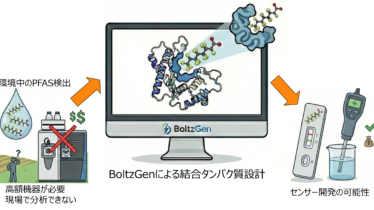 Pythonでインフォマティクス
Pythonでインフォマティクス 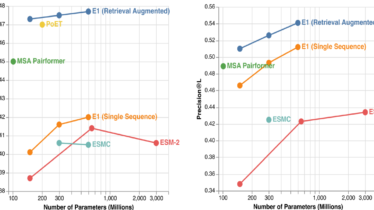 Pythonでインフォマティクス
Pythonでインフォマティクス 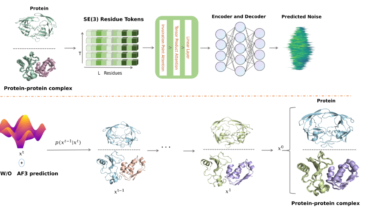 Pythonでインフォマティクス
Pythonでインフォマティクス 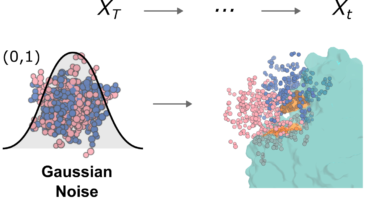 Pythonでインフォマティクス
Pythonでインフォマティクス  Pythonでインフォマティクス
Pythonでインフォマティクス