
データの解析において、複数のデータソースから情報を統合することは重要です。
この記事では、Rを使用してデータの結合(列の結合)を行う方法について紹介します。
データの結合は、データ解析において欠かせないステップです。今回は、列の結合(横の結合)を解説します。
1. 同じ行数で、異なる列名をもつデータ同士の列の結合 (cbind関数)
2. 行数が異なるデータの結合 (空のデータフレームをつくってcbind関数)
3. 共通の列名をもつデータの結合(merge関数が便利!)
1. 同じ行数で、異なる列名をもつデータ同士の列の結合(cbind関数)
同じ行数を持つ異なるデータを列で結合(横に結合)する方法を示します。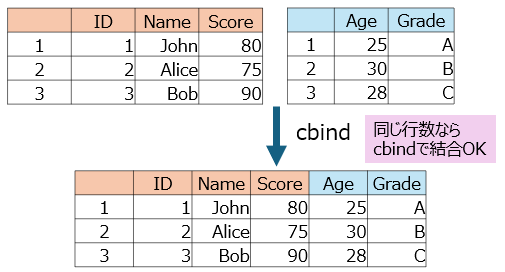
df1 <- data.frame(ID = 1:3, #3行×3列のデータフレームを作成
Name = c("John", "Alice", "Bob"),
Score = c(80, 75, 90))
df2 <- data.frame(Age = c(25, 30, 28), #3行×2列のデータフレームを作成
Grade = c("A", "B", "C"))
combined_df<-cbind(df1, df2)
combined_df
# ID Name Score Age Grade
#1 1 John 80 25 A
#2 2 Alice 75 30 B
#3 3 Bob 90 28 C
cbind関数で、横に結合できました。
行数が異なるデータ同士だとこちらのコードは通りません。。次の方法でやってみて下さい!
2. 行数が異なるデータの結合 (空のデータフレームをつくってcbind関数)
行数が異なるデータ同士を結合する場合は、上述のcbindでは、エラーが出てしまいます。。
そこで、行数の多いデータに合わせて空のデータフレームを作成し、cbindを実行する方法で実行します。

df3 <- data.frame(Age = c(25, 30),
Grade = c("A", "B"))
combined_df2<-cbind(df1, df3)
# data.frame(..., check.names = FALSE) でエラー:
# 引数に異なる列数のデータフレームが含まれています: 3, 2
n_rows <- nrow(df1) # df1が最大行数なので、df1の行数の空のデータフレーム(※)を作成
#最大行数が不明の場合は、n_rows <- max(nrow(df1), nrow(df3)) とすると、大きい行数で空のデータフレームを作成
empty_df3 <- data.frame(Age = rep(NA, n_rows), Grade = rep(NA, n_rows)) #df3の列名を※に入れる
empty_df3
# Age Grade
#1 NA NA
#2 NA NA
#3 NA NA
empty_df3[1:nrow(df3), ] <- df3 #空のデータフレームにデータを入れる
empty_df3
# Age Grade
#1 25 A
#2 30 B
#3 NA <NA> #3行目はないので、NAのまま
combined_df2<-cbind(df1, empty_df3) #結合
combined_df2
# ID Name Score Age Grade
#1 1 John 80 25 A
#2 2 Alice 75 30 B
#3 3 Bob 90 NA <NA>
行数がそろったデータ同士の列の結合ができました。
データがないところには欠損値としてNAが入ります。
次は、共通の列名の情報を基準としたデータ結合です!

3. 共通の列名をもつデータの結合 (merge関数が便利!)
同じ列名(キー)をもつデータの結合には、merge関数が便利です!
dplyrパッケージのinner_join関数(共通の行だけ残して結合)、left_join関数(左(先、x)のデータに右(後、y)のデータを結合(左にない行は消える))、などありますが、merge関数で同様の作業ができます!
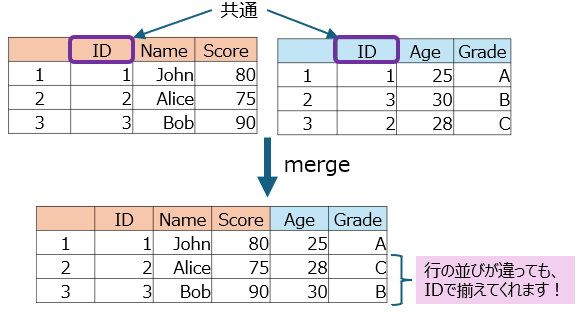
①行情報と行数が揃ってる(行の順番変化はOK)場合(merge関数使用)
df1 <- data.frame(ID = c(1, 2, 3),
Name = c("John", "Alice", "Bob"),
Score = c(80, 75, 90))
df1
# ID Name Score
#1 1 John 80
#2 2 Alice 75
#3 3 Bob 90
df4 <- data.frame(ID = c(1, 3, 2),
Age = c(25, 30, 28),
Grade = c("A", "B", "C"))
df4
# ID Age Grade
#1 1 25 A
#2 3 30 B
#3 2 28 C
merged_df <- merge(df1, df4, by = "ID") #IDで揃える。
merged_df
# ID Name Score Age Grade
#1 1 John 80 25 A
#2 2 Alice 75 28 C
#3 3 Bob 90 30 B
②行情報や行数が揃ってない場合(merge関数使用)
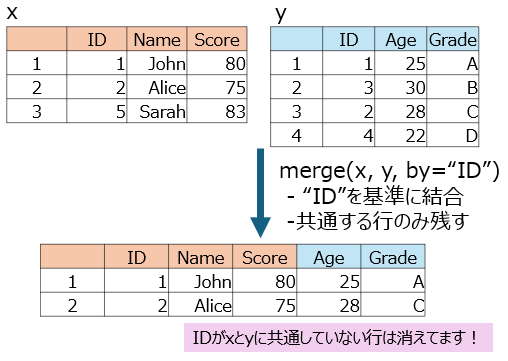
◆共通する行だけ残す方法(inner_join関数と同じ)
df4 <- data.frame(ID = c(1, 2, 5),
Name = c("John", "Alice", "Sarah"),
Score = c(80, 75, 83))
df5 <- data.frame(ID = c(1, 3, 2, 4),
Age = c(25, 30, 28, 22),
Grade = c("A", "B", "C", "D"))
merged_df2 <- merge(df4, df5, by="ID") ※
merged_df2
# ID Name Score Age Grade
#1 1 John 80 25 A
#2 2 Alice 75 28 C
#inner_join(df4, df5, by="ID") で同じmerged_df2を作成
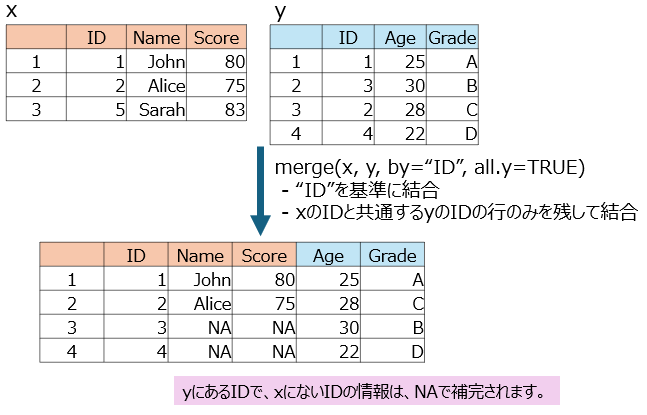
◆共通していない行も全部残す(情報がないところはNAで補完、all=TRUE使用、full_join関数と似てる)

merged_df3<-merge (df4, df5, by="ID", all = TRUE)
merged_df3
# ID Name Score Age Grade
#1 1 John 80 25 A
#2 2 Alice 75 28 C
#3 3 <NA> NA 30 B
#4 4 <NA> NA 22 D
#5 5 Sarah 83 NA <NA>
full_join(df4, df5, by="ID")
# ID Name Score Age Grade
#1 1 John 80 25 A
#2 2 Alice 75 28 C
#3 5 Sarah 83 NA <NA>
#4 3 <NA> NA 30 B
#5 4 <NA> NA 22 D #mergeとは順番が違うので注意
◆先データ(x)に後データ(y)を結合(先データにあるIDの行のみ残す、all.x=TRUE使用、left_join関数と同じ)

◆後データ(y)に先データ(x)を結合(後データにあるIDの行のみ残す、all.y=TRUE使用、right_join関数と同じ)
merged_df5<-merge (df4, df5, by="ID", all.x = TRUE) #先(df4, x)のデータに後(df5, y)のデータを結合。all.x=TRUEは、先のデータを全部残して、後のデータで先のデータと共通する"ID"の列のみを結合させる
merged_df5
# ID Name Score Age Grade
#1 1 John 80 25 A
#2 2 Alice 75 28 C
#3 5 Sarah 83 NA <NA>
# left_join(df4, df5, by="ID") 同じmerged_df5 を作成
merged_df6<-merge (df4, df5, by="ID", all.y = TRUE) #後(df5, y)のデータに先(df4, x)のデータを列結合。all.y=TRUEは、後のデータを全部残して、先のデータで後のデータと共通する"ID"の列のみを結合させる
merged_df6
# ID Name Score Age Grade
#1 1 John 80 25 A
#2 2 Alice 75 28 C
#3 3 <NA> NA 30 B
#4 4 <NA> NA 22 D
# right_join(df4, df5, by="ID") 同じmerged_df6 を作成
いろいろなパターンの列の結合を紹介しました。
作業で使用してみてください。
行の結合についても投稿していますので、こちらもご覧ください。

コメント