 Pythonでインフォマティクス
Pythonでインフォマティクス BoltzGen:設計と構造予測を統合したタンパク質の全原子生成AI
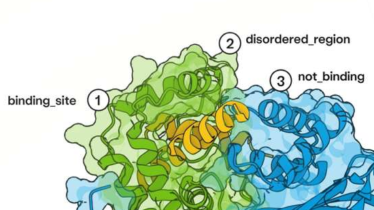
1. 研究の背景と目的タンパク質の構造と機能を自在に設計する技術は、創薬・バイオテクノロジー等の幅広い分野で大きな貢献が期待されています。特に、特定のターゲット分子に結合するタンパク質(バインダー)をゼロから設計するde novoタンパク質...
 Pythonでインフォマティクス
Pythonでインフォマティクス  Pythonでインフォマティクス
Pythonでインフォマティクス 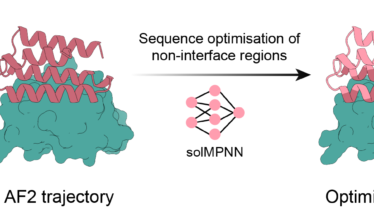 Pythonでインフォマティクス
Pythonでインフォマティクス  Pythonでインフォマティクス
Pythonでインフォマティクス  Rでデータ解析と可視化
Rでデータ解析と可視化  高校情報Ⅰ
高校情報Ⅰ 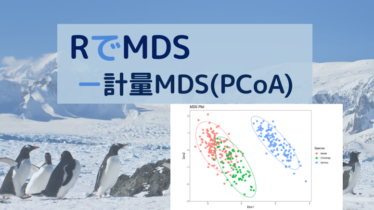 Rでデータ解析と可視化
Rでデータ解析と可視化  高校情報Ⅰ
高校情報Ⅰ  Pythonでインフォマティクス
Pythonでインフォマティクス  Rでデータ解析と可視化
Rでデータ解析と可視化