

微生物生態学や環境科学において、調査地点や処理区などの「グループ間で生物コミュニティに違いがあるか」を明らかにすることは、解析の最も重要な第一歩です。
以前、NMDSについてご紹介しました。

前回の記事ではNMDSの図を描くことに焦点を当てましたが、実際の研究では「図で見た目の差を確認する」だけでなく、その差が統計的に確かなものかという「裏付け」が求められます。
そこで今回は、2025年に発表された最新論文の手法を例に、より実践的な解析フローを解説します。
・Tinning, Z. et al. Dynamics of Bacterial and Vibrio Communities in Blacklip Rock Oysters in the Seasonal Tropics. Microb. Ecol. 88, 125, 2025, doi: 10.1007/s00248-025-02599-w
Tinning論文では、熱帯域の季節変動が、オーストラリア北部に生息するブラックリップ・ロックオイスター(カキ)とその周囲の海水の微生物コミュニティに与える影響を調査しています。
この論文では、以下の2つの対比が重要な解析ポイントとなっています。
・生体 vs 環境: カキの体内(軟体部)と、それを取り囲む海水における細菌叢の違い。
・季節変動: 雨季と乾季という季節変化が、病原性を持つ Vibrio 属菌などの動態にどう関わるか。
著者は、NMDSによる視覚化に加え、PERMANOVAやSIMPER解析を駆使して、これらのグループ間に統計的に有意な差があること、そしてその差を決定づけている主要な分類群について調べています。
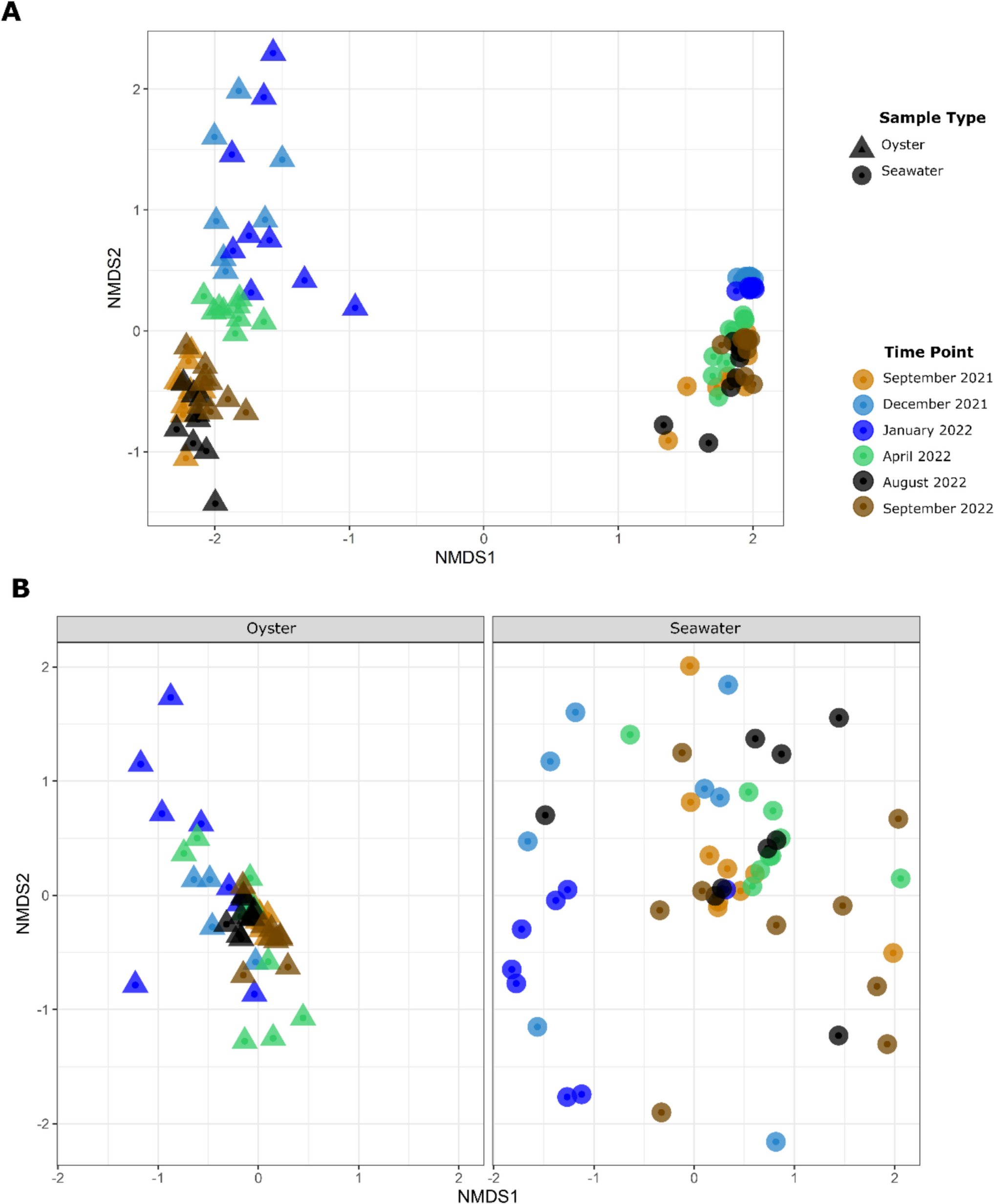
引用 Tinning論文
具体的には、データの偏りを補正する「平方根変換」を組み合わせたNMDSの作図から、グループ間の差異を検定するPERMANOVA、そして差の要因となる分類群(各生物種)を特定するSIMPER解析までを一挙にご紹介します。
解析をすぐにお手元で再現できるよう、Rのveganパッケージに含まれる標準データ(varespec)を用い、最短ルートで論文レベルの出力を目指しましょう。
目次
1. データの前処理:優占分類群の影響を抑える「平方根変換」
微生物のシーケンスリード数や各分類群の被覆率データには、「一部の種が圧倒的に多い」という偏りがつきものです。モデル論文に従い、まずはこれらの数値データに平方根(Square-root)変換を施します。これにより、優占分類群だけでなくコミュニティ全体の変動をバランスよく解析に反映させることができます。
NMDSの記事同様に、varespecのデータセットを使用します。
varespecは、トナカイを放牧する松林における地衣類やコケ植物などの下層植物と土壌特性に関するデータです。varespecは24行44列で構成され、列は44種の分類群の推定被覆率値の記録です。
library(vegan)
data(varespec)
# 論文に準拠した平方根変換
spe_sqrt <- sqrt(varespec)2. 可視化と検定:NMDS & PERMANOVA
次に、Bray-Curtis距離を用いて群集構造の違いを可視化し、その差が統計的に有意かを検証します。今回はサンプルを2つのグループに分けて検定を行います。
# 1. NMDSの実行(Bray-Curtis距離を使用)
nmds_res <- metaMDS(spe_sqrt, distance = "bray")
Wisconsin double standardization
Run 0 stress 0.1843196
Run 1 stress 0.2422452
Run 2 stress 0.221214
Run 3 stress 0.1825658
... New best solution
... Procrustes: rmse 0.04162665 max resid 0.1518072
Run 4 stress 0.2090731
Run 5 stress 0.2408587
Run 6 stress 0.2356303
Run 7 stress 0.18584
Run 8 stress 0.1948413
Run 9 stress 0.1948413
Run 10 stress 0.1982376
Run 11 stress 0.1948413
Run 12 stress 0.2659048
Run 13 stress 0.2401079
Run 14 stress 0.2109613
Run 15 stress 0.2100656
Run 16 stress 0.2151458
Run 17 stress 0.2368634
Run 18 stress 0.2109612
Run 19 stress 0.2266137
Run 20 stress 0.2134678
*** Best solution was not repeated -- monoMDS stopping criteria:
20: stress ratio > sratmax
モデル論文(Tinning et al. 2025)のような、形状や色を駆使したプロフェッショナルな図を作成するには、ggplot2 パッケージを使用します。
vegan で計算したNMDSの結果を ggplot2 で描画するには、プロット用の「座標データ」と「環境データ(メタデータ)」を一つの表(データフレーム)に結合する必要があります。モデル論文のような「サンプルタイプ(形状)」と「時期(色)」を組み合わせた図を作成してみましょう。
library(ggplot2)
library(dplyr) # データ操作用
# 1. NMDSの座標を抽出
nmds_scores <- as.data.frame(scores(nmds_res, display = "sites"))
# 2. メタデータの作成と結合(デモデータ)
# モデル論文の図を再現するため、仮のメタデータを作成します
# (varespecの24サンプルに合わせて12個ずつ割り当て)
site_info <- rep(c("Forest_A", "Forest_B"), each = 12) # 形状(Shape, Location)用
time_info <- rep(c("Period_1", "Period_2"), times = 12) # 色(Color, Period)用
nmds_data <- nmds_scores %>%
mutate(Site = site_info,
Time = time_info)
# 3. ggplot2による作図(基本形:一つのプロット)
nmds_basic <- ggplot(nmds_data, aes(x = NMDS1, y = NMDS2, shape = Site, color = Time)) +
geom_point(size = 5, alpha = 0.8) +
# 論文の形状に寄せる(17:三角, 16:丸)
scale_shape_manual(values = c(17, 16)) +
theme_bw() +
labs(title = "NMDS plot (Basic: Single Type)",
shape = "Location",
color = "Period") +
theme(plot.title = element_text(hjust = 0.5))
# 基本プロットの表示
print(nmds_basic)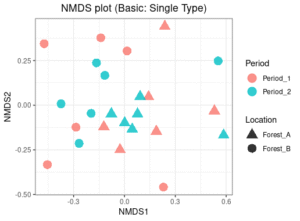
色別(Period)だと、混在傾向が見え、形別(Location)だと、Forest_Aの▲が中央から右側にかけてまとまる傾向があるように見えます。
次に、モデル論文に合わせて、グループに分けて詳細を見てみます。
Site(Location)のグループごと、つまり、ForestAとForestBに分けた形でNMDS図を表示して、Period(Time)グループについてみてみます。
# 4. ggplot2による作図(発展形:Locationのグループごとの分割図)
# モデル論文の図Bのように、グループ(Site(Location))ごとに分割(Facet)します
nmds_facet <- nmds_basic +
facet_wrap(~ Site, nrow = 1) + # グループ(Site(Location))で横に分割
# 軸のスケールを自動調整したい場合は scales = "free" を追加
labs(title = "NMDS plot (Advanced: Faceted Type)")
# 分割プロットの表示
print(nmds_facet)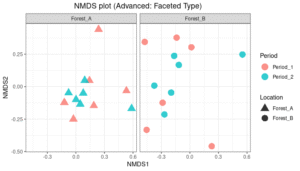
ForestAとForestBに分けた時、Period1とPeriod2は混在している傾向があるように見えます。
次に、Timeグループごと、つまりPeriod1とPeriod2で分けてSite(Location)の違いを見てみます。
# 5. ggplot2による作図(発展形:Period グループごとの分割図)
# モデル論文の図Bのように、グループ(Time(Period))ごとに分割(Facet)します
nmds_facet2 <- nmds_basic +
facet_wrap(~ Time, nrow = 1) + # グループ(Time(Period))で横に分割
# 軸のスケールを自動調整したい場合は scales = "free" を追加
labs(title = "NMDS plot (Advanced: Faceted Type(Period))")
# 分割プロットの表示
print(nmds_facet2)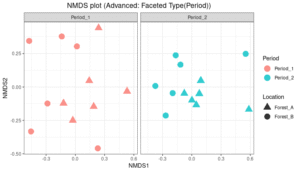
Period別でみると、Locationごとで、異なる傾向が見られました。
複数のグループがある場合は、モデル論文のように、グループごとに分けてみると見やすいこともあるので、ご参考にされてください。
要因をSite(ForestAとBの比較)に絞ってPERMANOVAとSIMPER解析を実行します。
※手順解説をシンプルにするため、Siteのみ紹介しますが、Timeについては、下記のSiteをTimeに変えていただければ、OKです。
# 乱数のシードを固定(数字は何でもOK)
set.seed(123)
# 6. PERMANOVAによる有意差検定
adonis2(spe_sqrt ~ Site, data = nmds_data, method = "bray", permutations = 999)
#Permutation test for adonis under reduced model
#Permutation: free
#Number of permutations: 999
#adonis2(formula = spe_sqrt ~ Site, data = nmds_data, permutations = 999, method = "bray")
# Df SumOfSqs R2 F Pr(>F)
#Model 1 0.44369 0.18456 4.9795 0.001 ***
#Residual 22 1.96029 0.81544
#Total 23 2.40398 1.00000
#---
#Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1NMDSによる各分類群の群集構造の可視化と、PERMANOVA(ADONIS)による統計的有意差の検定を行いました。
・群集構造の可視化 (NMDS):
2次元プロットにより、ForestAとForestBのサンプルが空間上で分離されている傾向が確認されました。これは、両グループ間で生物組成に違いがあることを視覚的に示唆しています。
・グループ間の統計学的有意差 (PERMANOVA):
検定の結果、グループ間には統計学的に有意な差が認められました(F = 4.98、p < 0.001)。説明力は、R2 = 0.185 であり、「グループの違い」が群集構造全体のバリエーションのうち約18.5%を説明していることが示されました。
3. 特定:SIMPERによる主要な分類群の炙り出し
統計学的に有意な差が確認できましたので、最後はSIMPER解析です。どの分類群がグループ間の違いに最も貢献しているのかを特定し、議論のエビデンスにします。
こちらもSite(Location)のグループ間における解析を行いました。
# 乱数のシードを固定(数字は何でもOK)
set.seed(123)
# SIMPER解析の実行
sim_res <- simper(spe_sqrt, nmds_data$Site)
# 寄与度の高い上位分類群を確認
summary(sim_res)
#Contrast: Forest_A_Forest_B
# average sd ratio ava avb cumsum p
#Cladstel 0.07306 0.05081 1.43770 1.14300 5.13100 0.154 0.004 **
#Pleuschr 0.05671 0.03555 1.59540 4.78000 1.60900 0.273 0.001 ***
#Cladrang 0.03723 0.02732 1.36300 2.81600 4.42300 0.351 0.027 *
#Cladarbu 0.03015 0.02139 1.40910 2.83800 2.85000 0.414 0.686
#Dicrfusc 0.02898 0.02586 1.12070 2.25800 0.78000 0.475 0.009 **
#Vaccmyrt 0.02019 0.02227 0.90660 1.12800 0.36400 0.517 0.064 .
#Empenigr 0.01972 0.01410 1.39810 2.33100 2.23600 0.559 0.966
#Callvulg 0.01764 0.01978 0.89180 1.09600 0.44400 0.596 0.213
#Vaccviti 0.01754 0.01260 1.39230 3.34000 3.16600 0.633 0.831
#Cladunci 0.01653 0.01875 0.88160 1.46600 0.82500 0.668 0.130
#Dicrsp 0.01467 0.02328 0.63030 0.68400 0.39500 0.698 0.521
#Stersp 0.01062 0.01318 0.80560 0.39400 0.63600 0.721 0.825
#Vacculig 0.01008 0.01245 0.80910 0.40600 0.37700 0.742 0.543
#Hylosple 0.00960 0.01793 0.53550 0.57600 0.01200 0.762 0.057 .
#Polyjuni 0.00842 0.00950 0.88660 0.44700 0.56000 0.780 0.911
#Flavniva 0.00835 0.01369 0.61000 0.05200 0.51400 0.797 0.013 *
#Ptilcili 0.00810 0.01110 0.72990 0.33100 0.46500 0.814 0.849
#Claddefo 0.00697 0.00559 1.24620 0.75000 0.37000 0.829 0.005 **
#Rhodtome 0.00643 0.00975 0.65960 0.30500 0.16700 0.843 0.306
#Dicrpoly 0.00603 0.00702 0.85870 0.24400 0.29800 0.855 0.875
#Descflex 0.00549 0.00795 0.69030 0.29800 0.12300 0.867 0.469
#Cladcris 0.00516 0.00476 1.08410 0.55900 0.39200 0.877 0.123
#Cetreric 0.00486 0.00375 1.29500 0.30100 0.26400 0.888 0.677
#Pinusylv 0.00435 0.00365 1.19290 0.28400 0.37600 0.897 0.169
#Diphcomp 0.00431 0.00634 0.68000 0.14200 0.16700 0.906 0.429
#Nepharct 0.00418 0.00921 0.45350 0.02400 0.25300 0.915 0.305
#Cetrisla 0.00402 0.00333 1.20740 0.10200 0.26500 0.923 0.111
#Pohlnuta 0.00358 0.00207 1.73210 0.30400 0.25600 0.931 0.109
#Cladcorn 0.00353 0.00330 1.06920 0.47400 0.45100 0.938 0.492
#Cladcocc 0.00321 0.00245 1.31300 0.28200 0.30300 0.945 0.644
#Cladchlo 0.00301 0.00264 1.14030 0.08700 0.19200 0.951 0.239
#Barbhatc 0.00299 0.00655 0.45730 0.06900 0.14400 0.957 0.352
#Cladgrac 0.00241 0.00243 0.98990 0.47000 0.41000 0.963 0.358
#Cladfimb 0.00227 0.00221 1.03000 0.38400 0.38000 0.967 0.897
#Cladphyl 0.00213 0.00333 0.63950 0.01900 0.12500 0.972 0.213
#Polypili 0.00208 0.00242 0.86140 0.06900 0.09100 0.976 0.402
#Peltapht 0.00205 0.00291 0.70450 0.09300 0.06400 0.980 0.667
#Cladbotr 0.00198 0.00187 1.05960 0.10000 0.04200 0.985 0.021 *
#Polycomm 0.00193 0.00282 0.68610 0.07700 0.07200 0.989 0.726
#Cladsp 0.00188 0.00202 0.92950 0.08100 0.08700 0.993 0.614
#Icmaeric 0.00108 0.00182 0.59510 0.03400 0.04100 0.995 0.948
#Betupube 0.00090 0.00201 0.44880 0.01200 0.05300 0.997 0.981
#Cladamau 0.00079 0.00148 0.53520 0.02400 0.02900 0.998 0.572
#Cladcerv 0.00075 0.00134 0.55830 0.00000 0.04500 1.000 0.183
#---
#Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#Permutation: free
#Number of permutations: 999SIMPER解析によって、ForestAとForestBの間の群集構造の差異に寄与している種を特定したところ、以下の知見が得られました。
・主要な寄与分類群:
群集間の差異に最も大きく貢献していたのは Cladstel (寄与率 15.4%)、次いで Pleuschr (寄与率 11.9%) でした。この上位2つの分類群だけで、グループ間の全差異の27.3%(累積寄与率)にあたり、全体の約4分の1以上を説明しています。これら上位2つの分類群はいずれも p < 0.01 であり、統計学的に確かな指標種であることが裏付けられました。
Cladstel は ForestB(平均 5.13)で ForestA(平均 1.14)よりも圧倒的に多く出現し、ForestBを象徴する分類群であることがわかります (p < 0.01)。一方、Pleuschr は ForestA(平均 4.78)で ForestB(平均 1.61)よりも多く、ForestAの特徴量として機能しています (p < 0.001)。
・2つのグループ間で統計学的有意性のある分類群:
上位の寄与分類群のうち、Cladstel、Pleuschr、Cladrang、Dicrfusc などが、グループ間での被覆率に統計的に有意な差(p < 0.05)を示しました。
4. まとめ:次のステップ「RDA」へ
今回の「平方根 + Bray-Curtis距離」という組み合わせは、多くの生態学論文で採用されている非常に安定した手法です。
・NMDS: 全体像を把握する。
・PERMANOVA: グループ間の差を証明する。
・SIMPER: グループ間の差を決める重要な分類群を特定する。
ここまででグループ間の違い、違いを決める分類群が分かりました。
次回の記事では、この違いを引き起こしている環境要因(pHや窒素など)との関係を解き明かすRDA(冗長性分析)に挑戦します!

コメント