
前回の記事で、Rの作業環境として、RStudioの基本的な使い方を説明しました。
今回は、RStudio上で、実際にRを動かします。
まずは、自前のデータをRに取り込みます。
といっても、どんなデータを使うの??ということで、誰もが使えるようなデータをwebから取ってきて実践しましょう。
誰もが使える、様々な公共データベースがあります!
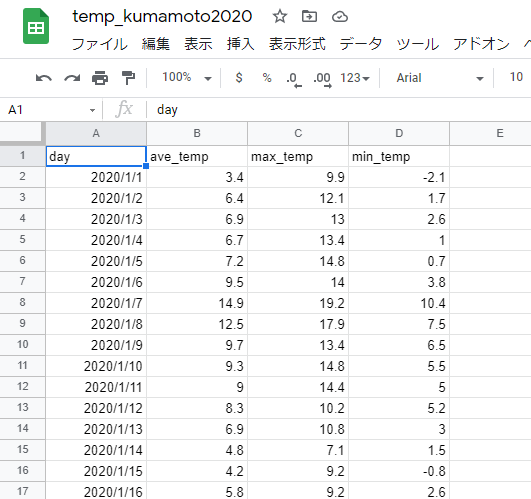
◆データの準備(csvファイル)
こちら、農林水産省の公表資料「令和元年農業総産出額及び生産農業所得」のデータをダウンロードして、Google ドライブに保存します。
保存されたGoogleドライブ上のデータの上で右クリックをして、 アプリ をクリック、Google スプレッドシート を選ぶと、Googleスプレッドシートで開くことができます。
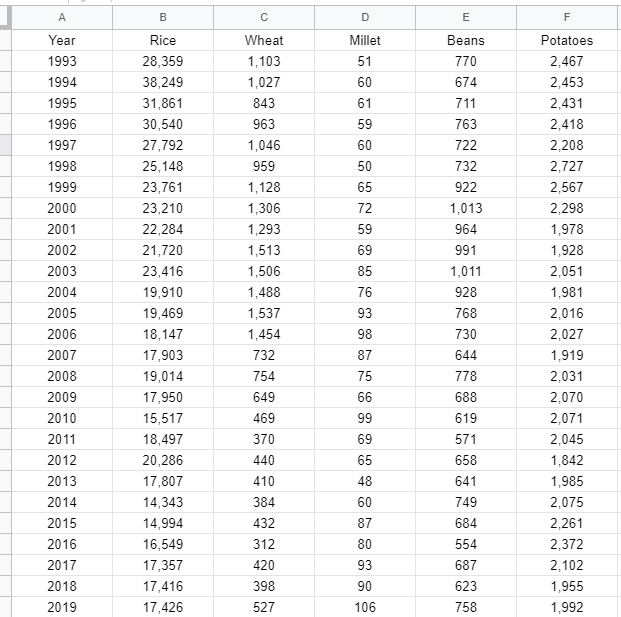
作業しやすいように、Google スプレッドシート上に以下のように年次別の生産農業所得のデータ(単位は億円)を作成して、Google スプレッドシートとして保存しました。
ファイル名はnougyosyotoku としました。(下の画像の左上のgoogle スプレッドシートの緑のマークの横をクリックすると直接ファイル名を入力できます。)
その後、以下のように、ファイル※1 → ダウンロード※2 → CSVファイル※ の形でダウンロードし、こちらのCSVをRに使用していきます。
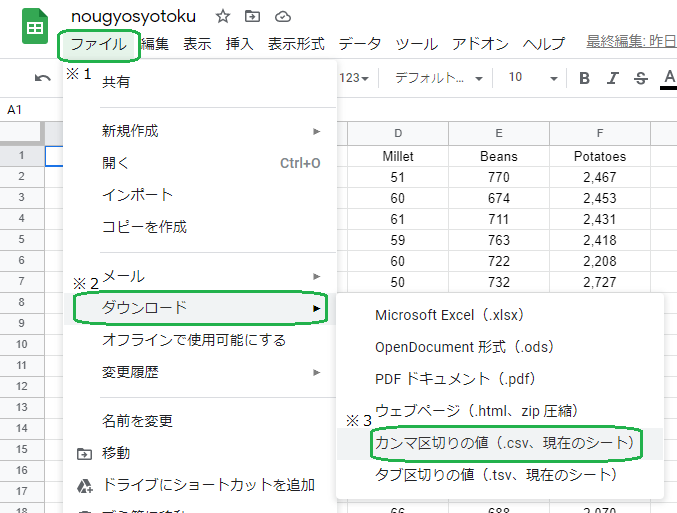
これで、PC>ダウンロードの中に nougyosyotoku – シート1.csv が作成出来ました。
以下、注意点です。
・Rでプレゼンテーションの前提として、無料で全部進めたい!ということでGoogleドライブ上の環境で進めていますが、もちろんExcelでCSVファイルを作成しても問題ありません。
・作業で読み込みなどでエラーがないよう、データやファイル名など英語表記のデータにしておくとよいです。
PC>ダウンロードの中にできた nougyosyotoku – シート1.csv は、先ほどのGoogleスプレッドシートの1枚目のシートからダウンロードした、ということでこのような名前になっています。
作業の都合上、ファイル名を変更し - シート1 は削除し、nougyosyotoku.csv とします。
こちらのファイルは作業する.Rprojと同じ場所に移してください。(ここではstudy_r.Rpojを使用していきます。)
nougyosyotoku.csv データを使って、Rでのデータの取り込みをやってみましょう。
◆データの取り込み
.Rproj をクリックすると、RStudioの画面が立ち上がります。
左上のR scriptか、 左下のConsoleにコードを入力してください。
> nougyosyotoku<-read.csv("nougyosyotoku.csv")
> exists("nougyosyotoku")
[1] TRUE
> head(nougyosyotoku)
Year Rice Wheat Millet Beans Potatoes
1 1993 28,359 1,103 51 770 2,467
2 1994 38,249 1,027 60 674 2,453
3 1995 31,861 843 61 711 2,431
4 1996 30,540 963 59 763 2,418
5 1997 27,792 1,046 60 722 2,208
6 1998 25,148 959 50 732 2,727
> dim(nougyosyotoku)
[1] 27 6
使用するコードは、read.csv(“ファイル名”)です。これにより、csvファイルをRに取り込むことができます。
nougyosyotoku<-read.csv(“nougyosyotoku.csv”)
A<-B は、BをAという名前にせよ。というコードです。A=B というコードも同じように使えます。
ちゃんと取り込めているかを確認するために、
exists(“nougyosyotoku”) を入力して、TRUE が返ってくれば取り込めたことを確認できます。
また、head(nougyosyotoku)で、nougyosyokuの最初の6行を表示してくれるので、データの中身も入っていることを確認できます。(私は、head()で確認することが多いです)
dim()で、行 列 (27行6列)の数情報から、確認することもできます。
どれかのコマンドで、ちゃんと読み込めたかを確認してください。
◆データを少し加工
―列指定
先ほど読み込んだnougyosyotoku をRで必要な箇所だけのデータに整理します。
今回は、YearとRice、Wheat、Potatesの列情報だけにしたい!その作業をやってみます。
> nougyosyotoku2<-subset(nougyosyotoku, select=c(Year,Rice,Wheat,Potatoes)) > head(nougyosyotoku2) Year Rice Wheat Potatoes 1 1993 28,359 1,103 2,467 2 1994 38,249 1,027 2,453 3 1995 31,861 843 2,431 4 1996 30,540 963 2,418 5 1997 27,792 1,046 2,208 6 1998 25,148 959 2,727
subset(ファイル名, select=c(列名1,列名2)) という形で入力すると、指定した列情報だけ抽出できます。
ー行指定
nougyosyotoku のデータから、2000年以降のデータだけ取り出します。
> nougyosyotoku3<-subset(nougyosyotoku, Year>=2000) > head(nougyosyotoku3) Year Rice Wheat Millet Beans Potatoes 8 2000 23,210 1,306 72 1,013 2,298 9 2001 22,284 1,293 59 964 1,978 10 2002 21,720 1,513 69 991 1,928 11 2003 23,416 1,506 85 1,011 2,051 12 2004 19,910 1,488 76 928 1,981 13 2005 19,469 1,537 93 768 2,016
subset(ファイル名, Year>=2000) これはYearの列で2000以上のデータだけ抽出せよ。ということです。
A>=B B以上のAを抽出 というコード
A>B Bより大きいAを抽出
◆データの出力(csvファイル)
先ほど作ったデータをcsvファイルとして出力する作業をこれから説明します。
> write.csv(nougyosyotoku2, "nougyosyotoku2.csv") > write.csv(nougyosyotoku3, "nougyosyotoku3.csv")
write.csv(Rの上のデータ, “保存したいファイル名.csv”)で、csvファイルを作成できます。
どこにできたのか?は、.Rprojがあるフォルダにnougyosyotoku2.csvとnougyosyotoku3.csv ができています。ご確認ください。
Google スプレッドシートで開くと、下のような感じです。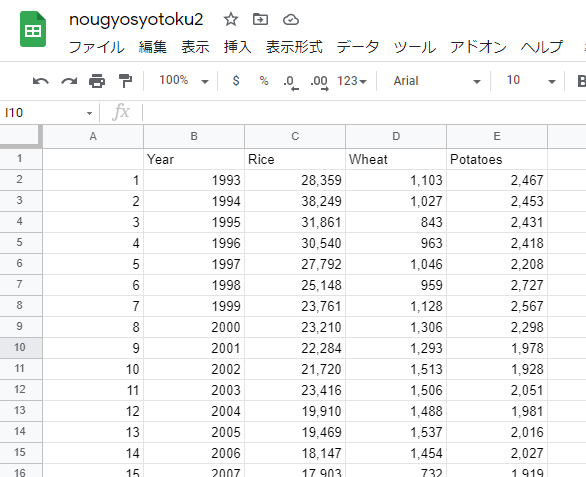
今回は、CSVファイルでのデータ取り込みとデータを少し加工、そしてデータ作成を行いました。
ファイル形式とエクセルファイルの読込みについては、以下の記事でも解説していますので、参考にしてください。
☆コラム 〜Rには練習用データセットがたくさんあります〜☆
Rには、解析作業を取り組むために、練習用データが保存されています。
こちらにはたくさんのデータセットがあります。
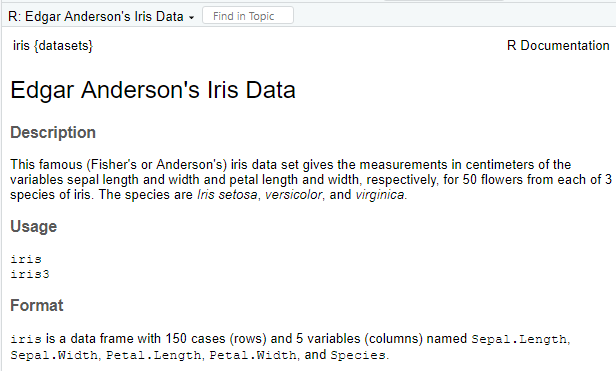
例えば、有名なiris(あやめ)のデータは以下のようにすぐに使えます。
help(iris)
このデータがどんなものか知りたければ、help(データセット) で右下にデータセットの説明が出てきます。
View(iris)
View(データ)で、左上にデータを出してみることもできます。
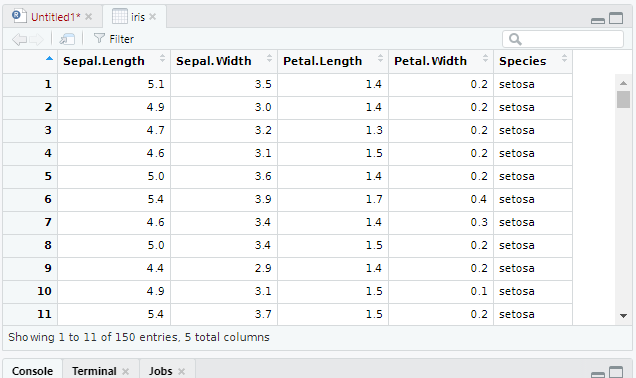
これは、データセットだけでなく、先ほどのnougyosyotoku などの、自分が作成したデータでも表示できます。
Rに保存されているデータセットを使っての、解析や可視化の作業は下記の記事等を参考にしてください。

コメント