
データの取り込みについては、以下に投稿しています。
Rを活用して、誰にでもわかりやすく解析結果を共有出来る資料につなげていきたいと思います。
今回取り組むのは、ヒストグラム ( 度数分布を表すグラフで、あるデータ区間ごとに存在するサンプルの数を棒グラフで表したもの)です。
ヒストグラムから何が言えて、どのように考察できるのか、をプレゼンテーションできるよう作成します。
◆データセットについて
Rにはスムーズに勉強を進められるdatasetが入っています。
以下のThe R Datasets Package を参考にしてください。
https://stat.ethz.ch/R-manual/R-patched/library/datasets/html/00Index.html
最も活用されているdatasetにirisデータがあります。
iris と入れるだけで、すぐにデータセットを使用できます。
head(iris) #irisデータの冒頭部分を確認 Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa class(iris) #データ形式 [1] "data.frame" help(iris) #irisデータの情報
help(iris)のコマンドで、右下の区画に以下のようにirisに関する情報が表示されます。
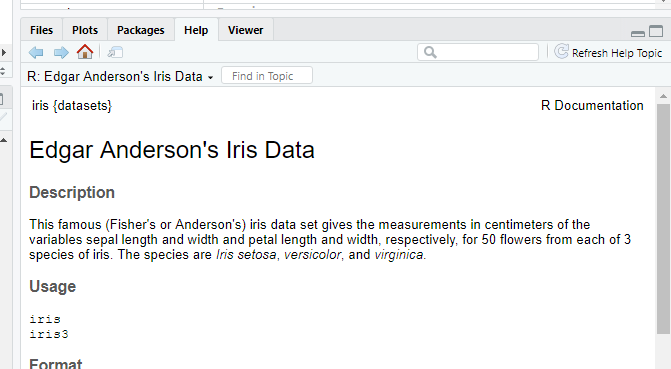
iris は、setosa(ヒオウギアヤメ), versicolor, virginicaの3種のあやめの花をそれぞれ50ずつ調べ、がくと花びらの長さと幅を計測した結果を入力したものです。
項目名は左から、サンプル番号、Sepal.Length(がくの長さ)、Sepal.Width(がくの幅)、Petal.Length(花びらの長さ)、Petal.Width(花びらの幅)、あやめの種類となっています。
◆ヒストグラムの作成
hist(iris$Sepal.Width, main="Histgram of sepal.width", col="green4") #① hist(iris$Sepal.Length, main="Histgram of sepal.length", col="green3") #② hist(iris$Petal.Length, main="Histgram of petal.length", col="violet") #③ hist(iris$Petal.Width, main="Histgram of petal.width", col="violetred4") #④
「ヒストグラムの作成」のコマンドとして 「hist()」を使用します。
iris$Sepal.Width, iris dataのSepal.Widthの列、main=”グラフの名前”、col=”指定したい色”、というコマンドです。
※色については以下を参考にされてもよいかと思います。
#①~④のヒストグラムは以下の通りです。
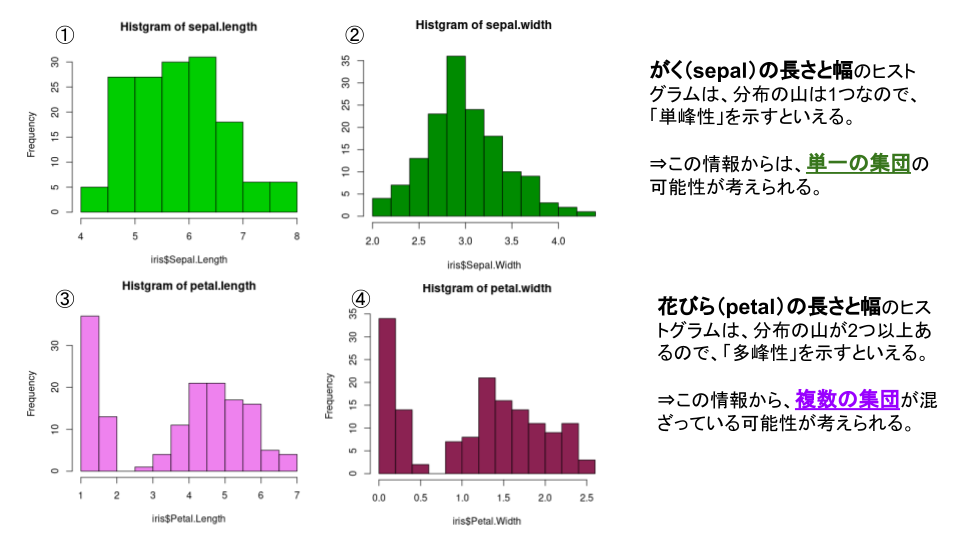
①と②から言えることと、⇒考察を書きました。
Rで可視化して、何が言えて、どう考えられるのか、という形で説明(プレゼンテーション)へとつなげていきます。
がくのヒストグラムの情報だけでは見えなかったですが、花びらのヒストグラムの情報から、複数の集団が混ざっている可能性が考えられました。
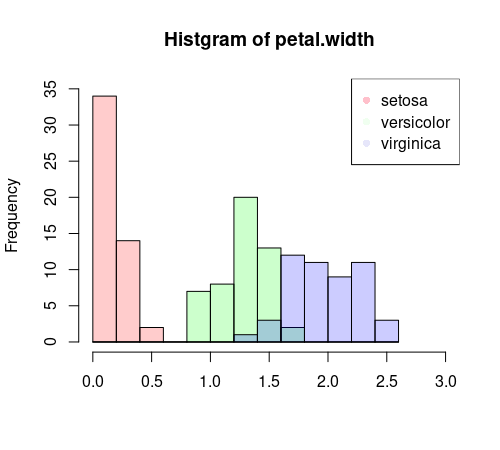
次に、複数の集団が混ざっていると考察された花びらの幅について、setosa, versicolor, virginicaの3種について色分けしてヒストグラムにしてみます。
iris_setosa<-subset(iris, iris$Species=="setosa") #setosaだけのデータに head(iris_setosa) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa nrow(iris_setosa) #setosaだけの50個のデータに。これでダブルチェック [1] 50 iris_versicolor<-subset(iris, iris$Species=="versicolor") #versicolorだけのデータに iris_virginica<-subset(iris, iris$Species=="virginica") #virginicaだけのデータに
「列の抜き出し」は「subset()」を使います。
subset(データ名, データ名$列名==”この列の中にあるあやめの種類の指定”)
hist(iris_setosa$Petal.Width,
col=rgb(1, 0, 0, alpha=0.2), #col = rgb(赤,緑,青) で色を指定した
main="Histgram of petal.width", #タイトル
xlab="", #X軸のラベルは表示しない。
xlim=c(0,3), ylim=c(0,35), #X軸、Y軸の最小と最大目盛
breaks=c(0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6, 1.8, 2, 2.2, 2.4,2.6)) # X軸の各棒グラフの分割目盛
hist(iris_versicolor$Petal.Width, col=rgb(0, 1, 0, alpha=0.2), breaks=c(0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6, 1.8, 2, 2.2, 2.4,2.6), add=T) #add=Tで上の図に重ねて表示
hist(iris_virginica$Petal.Width, col=rgb(0, 0, 1, alpha=0.2), breaks=c(0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6, 1.8, 2, 2.2, 2.4,2.6), add=T)
legend("topright", legend=c("setosa","versicolor","virginica"), col=c("pink", "honeydew1", "lavender"), pch=16) #凡例
ヒストグラムに「凡例(図のプロットや棒グラフの説明)の記載」は、「legend()」で行いました。
pch=は、凡例に表示するプロットの形を指定し、pch=16は ● です。
※プロットの形の指定は、以下を参考にされたらと思います。
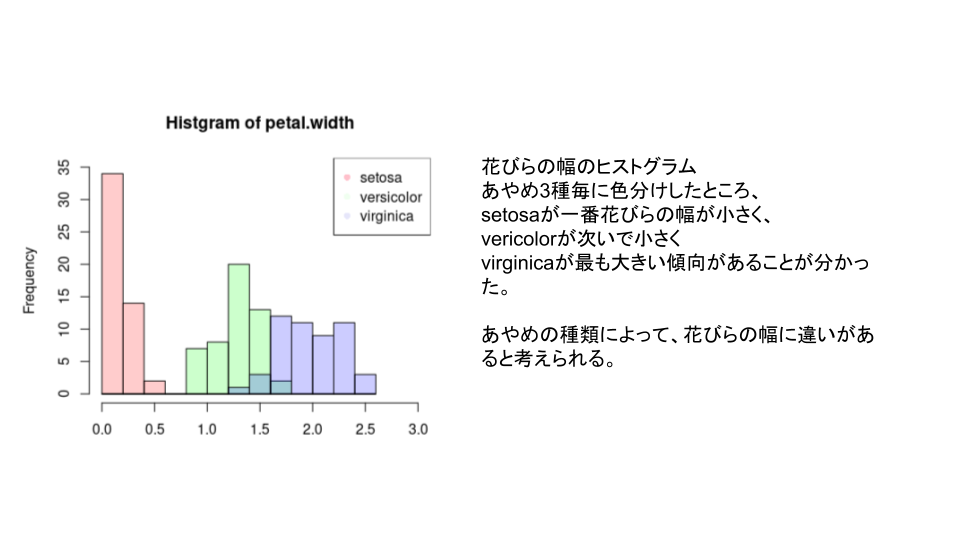
全体のヒストグラムを作成したところ、花びらに関するヒストグラムにおいて複数の集団が混ざっていることが分かりました。
花びらの幅においてあやめ3種を色分けして表示したところ、種類によって大きさが異なる傾向がみられ、種類によって花びらの幅に違いがあると考察できました。
このように、可視化によってみえること、考察できることをまとめることで、データを活用することができます。
次からも、Rのデータセットを使って、可視化と考察を行い、プレゼンテーション資料を作成します。

コメント