
クラスター分析の主な目的は、サンプルのデータの類似性やパターンに基づいて、サンプルをグループに分けることです。
クラスター分析は教師なし学習であり、サンプルに対してあらかじめ定義されたラベルやカテゴリがなくても、サンプルをグループ分けすることができます。
前回の投稿では、クラスター分析の階層クラスター分析について記載しました。

今回は、非階層クラスター分析を紹介します。
非階層クラスター分析と階層クラスター分析にはいくつかの違いがあります。
階層クラスター分析は、サンプル同士の類似度に基づき、段階的にグループを作っていく手法で、最終的にツリー状の構造(デンドログラム)として表示され、デンドログラムを基にクラスター数を決定します。
一方、非階層クラスター分析は、あらかじめ設定したクラスター数に基づき、サンプルを最適なグループに分ける手法です。
1. 非階層クラスター分析
今回紹介する非階層クラスター分析は、分割または重心をベースとしたクラスター化とも呼ばれ、階層構造をとらず、類似したサンプルをグループ化してクラスターを作る手法です。
データ量が多く、階層構造で分類が難しい場合に使用されます。
今回は、非階層クラスター分析手法の代表的なアルゴリズムであるk平均法(k-means法)を用いた例を紹介していきます。
k平均法を使用した非階層クラスター分析は、クラスター内の分散を最小限に抑えてデータを個別のクラスターに分割することを目的とした反復プロセスです。
データセット内のパターンや構造を明らかにするために、機械学習、データマイニング、顧客セグメンテーションなどのさまざまな分野で広く使用されています。
k平均法は、以下のアルゴリズムでクラスターを作成します。
①クラスター数の指定:
クラスター数(k)を選択します。クラスター数は事前の知識に基づいて決定、あるいはシルエット分析やエルボー法などで決定します。
k個のクラスター重心をランダムに初期化します。これらの重心は最初はデータセット内のランダムなデータポイントまたは位置に配置されます。
※シルエット分析については、階層クラスター分析の記事でも解説しています。
②割り当て:
各データポイントについて、k個の重心のそれぞれまでの距離を計算します。
各データポイントを、最も近い重心に関連づけられたクラスターに割り当て、k個のクラスターを形成します。
③重心の更新:
各クラスター内のすべてのデータポイントの平均(重心)を計算し、各クラスターの重心を計算された平均値によって、割り当てのクラスターを変更します。
④ ②と③を繰り返し:
②と③を、収束するまで繰り返すか、事前に定義する反復数に達するかで、繰り返しが停止します。
⑤最終クラスター:
k平均法アルゴリズムが停止すると、最終的なクラスターが得られます。
2. k平均法 データセットwine.dataを使用
ワインの使用データセットはwine.data(UC Irvine Machine Learning Repository保有)です。


wine.dataには、178種のwineの情報が含まれていて、各ワインの情報としては、以下の13項目あります。
1) Alcohol(アルコール)、 2) Malic acid(リンゴ酸)、 3) Ash(灰分)、 4) Alcalinity of ash(灰のアルカリ度)、 5) Magnesium(マグネシウム)、 6) Total phenols(総フェノール量)、 7) Flavanoids(フラバノイド)、 8) Nonflavanoid phenols(非フラバノイドフェノール類)、 9) Proanthocyanins(プロアントシアニン)、 10)Color intensity(色の濃さ)、 11)Hue(色相)、 12)OD280/OD315 of diluted wines(希釈ワインのOD280/OD315)、 13)Proline(プロリン)
ワイン3種が、1列目(V1)に1~3がラベリングされているので、最後にクラスター分析で答え合わせしてみます。
今回は、ワイン3種の分類データがあるので、どの程度分類が一致するかを確認するため、クラスター数を3と指定してクラスター分析を実施します。
library(stats) #1 libraryの読み込み
wine_data <- read.csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data", header = F) #2 wine_dataを読み込む
head(wine_data)
# V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12
# 1 1 14.23 1.71 2.43 15.6 127 2.80 3.06 0.28 2.29 5.64 1.04
# 2 1 13.20 1.78 2.14 11.2 100 2.65 2.76 0.26 1.28 4.38 1.05
# 3 1 13.16 2.36 2.67 18.6 101 2.80 3.24 0.30 2.81 5.68 1.03
# 4 1 14.37 1.95 2.50 16.8 113 3.85 3.49 0.24 2.18 7.80 0.86
# 5 1 13.24 2.59 2.87 21.0 118 2.80 2.69 0.39 1.82 4.32 1.04
# 6 1 14.20 1.76 2.45 15.2 112 3.27 3.39 0.34 1.97 6.75 1.05
# V13 V14
# 1 3.92 1065
# 2 3.40 1050
# 3 3.17 1185
# 4 3.45 1480
# 5 2.93 735
# 6 2.85 1450
wine_data_all<-wine_data[, 2:14] #3 V2以降が上記13項目の列に絞る
wine_data_all_sc<-scale(wine_data_all) #4 データの標準化
# V2 V3 V4 V5 V6 V7 V8 V9
#[1,] 1.5143408 -0.56066822 0.2313998 -1.1663032 1.90852151 0.8067217 1.0319081 -0.6577078
#[2,] 0.2455968 -0.49800856 -0.8256672 -2.4838405 0.01809398 0.5670481 0.7315653 -0.8184106
#[3,] 0.1963252 0.02117152 1.1062139 -0.2679823 0.08810981 0.8067217 1.2121137 -0.4970050
#[4,] 1.6867914 -0.34583508 0.4865539 -0.8069748 0.92829983 2.4844372 1.4623994 -0.9791134
#[5,] 0.2948684 0.22705328 1.8352256 0.4506745 1.27837900 0.8067217 0.6614853 0.2261576
#[6,] 1.4773871 -0.51591132 0.3043010 -1.2860793 0.85828399 1.5576991 1.3622851 -0.1755994
# V10 V11 V12 V13 V14
#[1,] 1.2214385 0.2510088 0.3611585 1.8427215 1.01015939
#[2,] -0.5431887 -0.2924962 0.4049085 1.1103172 0.96252635
#[3,] 2.1299594 0.2682629 0.3174085 0.7863692 1.39122370
#[4,] 1.0292513 1.1827317 -0.4263410 1.1807407 2.32800680
#[5,] 0.4002753 -0.3183774 0.3611585 0.4483365 -0.03776747
#[6,] 0.6623487 0.7298108 0.4049085 0.3356589 2.23274072
set.seed(1)
km1<-kmeans(wine_data_all_sc, centers=3)#5 クラスターを3つとする
km1 #6 クラスターの内訳
# K-means clustering with 3 clusters of sizes 51, 65, 62
# Cluster means: #7
# V2 V3 V4 V5 V6 V7 V8
# 1 0.1644436 0.8690954 0.1863726 0.5228924 -0.07526047 -0.97657548 -1.21182921
# 2 -0.9234669 -0.3929331 -0.4931257 0.1701220 -0.49032869 -0.07576891 0.02075402
# 3 0.8328826 -0.3029551 0.3636801 -0.6084749 0.57596208 0.88274724 0.97506900
# V9 V10 V11 V12 V13 V14
# 1 0.72402116 -0.77751312 0.9388902 -1.1615122 -1.2887761 -0.4059428
# 2 -0.03343924 0.05810161 -0.8993770 0.4605046 0.2700025 -0.7517257
# 3 -0.56050853 0.57865427 0.1705823 0.4726504 0.7770551 1.1220202
# Clustering vector: #8
# [1] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
#[44] 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 2 2 1 2 2 2 2 2 2 2 2 2 2 2 3 2 2 2 2 2 2 2 2 2 1 2 2
#[87] 2 2 2 2 2 2 2 2 2 3 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 3 2 2 2 2 2 2 2
#[130] 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
#[173] 1 1 1 1 1 1
# Within cluster sum of squares by cluster: #9
#[1] 326.3537 558.6971 385.6983
#(between_SS / total_SS = 44.8 %)
# Available components: #10
#[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
#[6] "betweenss" "size" "iter" "ifault"
#4 各項目のデータの大きさが大きく異なるので、標準化を行う
#6 3つのクラスターそれぞれに属するサンプル数
#7 各列(項目)における、各クラスターごとの平均(重心)。1⇒クラスター1の平均、2⇒クラスター2の平均、3⇒クラスター3の平均。
#8 各サンプルが属するクラスター
#9 品質を評価 各クラスターの平均値ベクトルからの偏差平方和、変動を説明する割合(説明率)
#10 関数の出力でアクセスできる要素。km1$centers など
library(cluster) #1 library読み込み
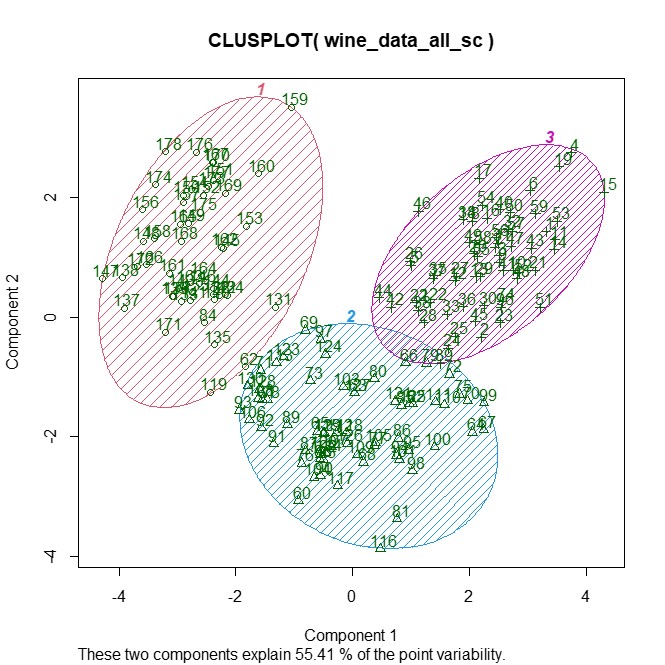
clusplot(wine_data_all_sc, km1$cluster, color=TRUE, shade=TRUE, labels=2, lines=0) #2
answer <- wine_data[,1]
result <- km1$cluster
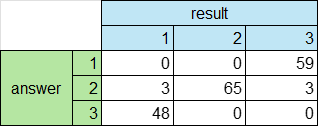
table <- table(answer, result)
#table #3
# result
# answer 1 2 3
# 1 0 0 59
# 2 3 65 3
# 3 48 0 0
#2 labels=2でプロットでは点と楕円にラベル
#3 answerは、データセットに含まれるワイン3種の分類データ
resultは、k平均法による分類データ
answerの1がresultの3、answerの2がresultの2、answerの3がresultの1であることが分かります。
ワイン3種が、与えられた項目情報によるクラスター分類による分類に近い結果であり、サンプルの大部分を効果的にグループ化できたといえます。
ワイン3種の化学成分がそれぞれ異なる傾向があって、クラスタリングのアルゴリズムでそれぞれにグループ化された可能性が考えられます。これにより、データに基づく非階層クラスター分析により、ワインの分類が可能であることが示唆されました。
ぜひ、他のデータセットにも本手法を応用してみてください。参考にしていただけると幸いです。参考書籍▼▼



コメント