
実験や調査の計画段階で「どのくらいのサンプル数が必要か?」を悩んだことはありませんか?
サンプルサイズを適切に設定することは、結果の信頼性を左右する重要なポイントです。
この記事では、Rを使って簡単にサンプルサイズを計算する方法を紹介します。
精度の高いデータ収集で計画をより確かなものにするために参考にしていただけたらと思います。


Rでサンプルサイズを計算する方法を解説していきます。
1. サンプルサイズをあらかじめ算出する重要性
2. サンプルサイズ算出の代表的な2つの手法
3. 区間推定におけるサンプルサイズ決定(標準偏差、許容誤差、信頼水準)①の特徴
4. 疫学研究のためのサンプルサイズの計算例
5. アンケート調査のためのサンプルサイズの計算例
6. サンプルサイズを可視化ー許容誤差を変化させてみるー
1. サンプルサイズをあらかじめ算出する重要性
適切なサンプルサイズをあらかじめ算出しておくことは、研究の成功や信頼性を大きく左右します。
・検出力の確保:
サンプルサイズが小さすぎると、真の効果を見逃す(検出力不足)可能性が高まります。これにより、有効な治療法や薬の効果を誤って否定してしまうリスクが生じます。
・資源や労力などのリソースの効率化:
サンプルサイズを適切に計算しておくことで、試験に必要な参加者数や時間、コストを予測できます。過剰なサンプルサイズはリソースの無駄に繋がり、逆に不足したサンプルサイズでは無意味な試験結果となる可能性があります。
・結果の信頼性向上:
適切なサンプルサイズで試験を行うことで、得られた結果が信頼性の高いものになります。これは特に臨床試験や疫学調査などの分野で重要で、信頼できる結論を導くためには適正なサンプルサイズが不可欠です。
・倫理的な観点:
臨床試験においては、試験参加者に対して不必要に大きなリスクを負わせることを避けるため、必要な最小限のサンプルサイズで試験を行うことが倫理的にも求められます。過剰な試験参加者を集めることは倫理的に問題があり、逆に少なすぎるサンプルでは参加者に不必要なリスクを負わせる結果になります。
2. サンプルサイズ算出の代表的な2つの手法
サンプルサイズの算出方法について、代表的な2種類を紹介します。
①区間推定におけるサンプルサイズ決定(標準偏差、誤差の許容範囲、信頼水準)
この方法は、母集団の平均や割合などのパラメータを推定する際に使用されます。標準偏差や許容誤差を考慮して、推定の精度を保証するためにサンプルサイズを計算します。アンケート調査や疫学研究など、推定が主目的の試験で多く用いられます。
② 仮説検定におけるサンプルサイズ決定(検出力、有意水準、効果量を用いた分析)
この方法は、統計的仮説検定に基づいてグループ間の差や効果の有無を検証する際に使用されます。サンプルサイズ、効果量、検出力を組み合わせて、仮説検定で真の効果をどれだけの確率で検出できるかを評価する手法です。特に、臨床試験や介入研究、実験研究などで頻繁に用いられ、効果を正確に検出するために必要なサンプルサイズの算出が重要です。
これら2つの手法は、それぞれ異なる目的に応じてサンプルサイズを決定するための代表的な方法であり、目的に応じて適切に選ぶことが重要です。
本記事では①区間推定におけるサンプルサイズ決定(標準偏差、誤差の許容範囲、信頼水準)に関する手法を参考例を交えながらRのコードの解説をしていきます。
3. 区間推定におけるサンプルサイズ決定(標準偏差、許容誤差、信頼水準)①の特徴
この手法は、推定精度を確保したい場合に広く使われます。たとえば、あるパラメータの平均や割合を推定し、その推定値がどの程度信頼できるか(信頼区間)を知りたい場合に使用されます。
・主な使用例: アンケート調査、疫学研究、製品の品質管理など
・目標: 母集団のパラメータ(平均、割合など)を一定の精度で推定すること
・特徴: 標準偏差や許容誤差が既に分かっている場合に適しており、精度に焦点を当てる研究で用いられます。
4. 疫学研究のためのサンプルサイズの計算例
疫学研究とは、一般的に集団における健康関連の要因や疾病の発生を調査・分析する分野です。例えば、臨床疫学において、臨床試験で健康指標である平均血圧を推定するためのサンプルサイズを、以下の条件で計算してみます。
標準偏差(血圧のばらつき σ): 20 mmHg(前情報などから想定)
誤差の許容範囲(許容誤差 E): ±5 mmHg
信頼水準: 95%に設定(Z値 = 1.96、※Rで算出可能)
これらの条件に基づき、血圧の推定に必要なサンプルサイズ(n)は以下の計算式で求められます。
サンプルサイズ計算式:
n = (Z ⋅ σ / E)2
この計算式を使用して、血圧のばらつきを考慮しながら、推定に必要なサンプルサイズを算出することができます。

# 95%の信頼水準の場合のZ値を求める ※ confidence_level <- 0.95 alpha <- 1 - confidence_level # 片側分布の臨界値を求めるため、alpha/2を使用 Z <- qnorm(1 - alpha / 2) Z # [1] 1.959964 #1.96を算出 # 各パラメータ設定 sigma <- 20 # 標準偏差 E <- 5 # 許容誤差(誤差の範囲) Z <- 1.96 # 信頼水準95%に対応するZ値 # サンプルサイズの計算 n <- (Z * sigma / E)^2 n # [1] 61.4656 #必要なサンプルサイズ
この試験では、標準偏差20 mmHg、誤差の許容範囲±5 mmHg、信頼水準95%という条件に基づいて、62サンプルが試験に必要と計算されました。
5. アンケート調査のためのサンプルサイズの計算例
ある企業が顧客満足度を調査し、調査結果の平均満足度を±0.1の誤差範囲内で推定したいとします。過去の調査では、満足度の標準偏差は0.3であると推定されています。信頼水準を95%に設定し、必要なサンプルサイズを計算します。
・顧客満足度の標準偏差 σ = 0.3
・許容誤差 E = 0.1
・95%信頼水準 Z = 1.96
サンプルサイズ計算式:
n = (Z ⋅ σ / E)2
# パラメータ設定
sigma2 <- 0.3 # 顧客満足度の標準偏差
E2 <- 0.1 # 許容誤差(±0.1)
Z2 <- 1.96 # 信頼水準95%に対応するZ値
# サンプルサイズの計算
n2 <- (Z2 * sigma2 / E2)^2
n2
#[1] 34.5744
この市場調査の例では、顧客満足度の標準偏差が0.3、許容誤差が±0.1、信頼水準95%という条件で、サンプルサイズが35であることが計算されました。サンプルサイズは、調査結果が指定した精度で推定できるために必要な数を示します。この計算により、信頼性のある推定を行うために必要な最小限のサンプル数を事前に算出することが可能です。
6. サンプルサイズを可視化ー許容誤差を変化させてみるー
5. アンケート調査のためのサンプルサイズの計算例での、顧客満足度の標準偏差を0.3、信頼水準を95%に固定し、許容誤差を変化させた場合のサンプルサイズの変化をグラフで示します。
library(ggplot2)
# パラメータ設定
sigma <- 0.3 # 顧客満足度の標準偏差
Z <- 1.96 # 信頼水準95%に対応するZ値
# 許容誤差の範囲を設定
errors <- seq(0.01, 0.5, by = 0.01)
# 許容誤差に対するサンプルサイズを計算
sample_sizes <- (Z * sigma / errors)^2
# データフレームにまとめる
data <- data.frame(errors = errors, sample_sizes = ceiling(sample_sizes))
data
# errors sample_sizes
#1 0.01 3458
#2 0.02 865
#3 0.03 385
#4 0.04 217
#5 0.05 139
#6 0.06 97
#7 0.07 71
#8 0.08 55
#9 0.09 43
#10 0.10 35
#11 0.11 29 ・・・
# サンプルサイズの可視化
ggplot(data, aes(x = errors, y = sample_sizes)) +
geom_line(color = "blue", size = 1.2) +
labs(title = "許容誤差とサンプルサイズの関係",
x = "許容誤差",
y = "必要なサンプルサイズ") +
theme_classic() #図
許容誤差が小さくなるほどサンプルサイズ数は多く必要になります。
例えば、許容誤差が0.1の場合は、サンプルサイズ35で、許容誤差が0.05の場合はサンプルサイズ139です。
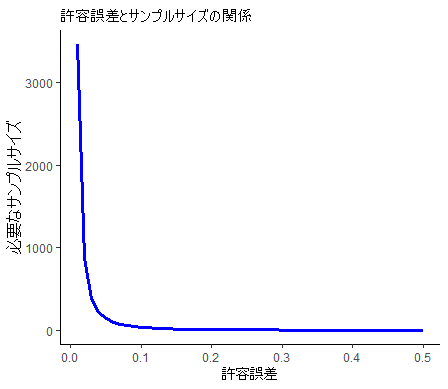
可視化によって、より理解しやすくなりました。
② 仮説検定におけるサンプルサイズ決定(検出力、有意水準、効果量を用いた分析)についても、後日解説記事を作成予定です。
他にも、Rでの解析や可視化に関するコード例を含む記事をあげていますので、ご参考にしていただけると幸いです。

Rを用いたデータ解析や可視化方法について、コード例を含めた解説記事を投稿しています。


コメント